




As a developer, the source code that you write is all so concise and elegant. And other developers can read, and understand your code with ease. However, a compiler has to do a lot more to make sense of your code.
In this post, you’ll learn how compilers try to understand what your code does, and focus on what an Abstract Syntax Tree (AST) is, and its relevance to static analysis.
How does the compiler make sense of your code?
The steps involved in the compiler’s processing of source code are illustrated below:
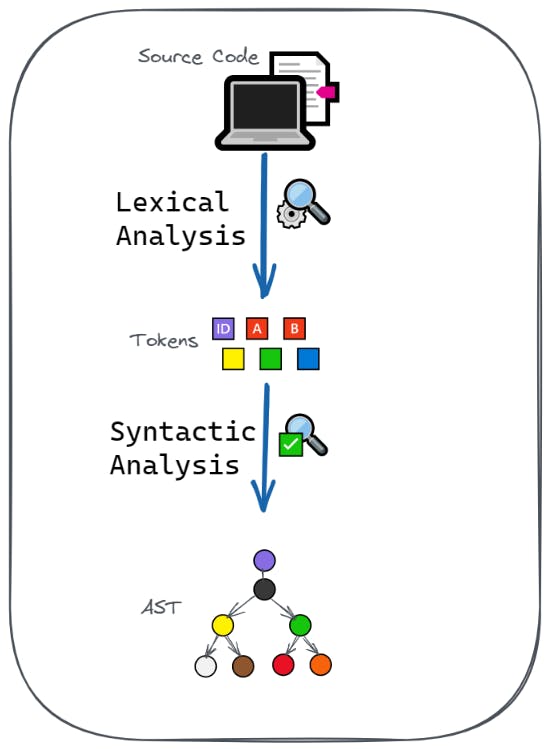
Let’s expand on this a bit.
The source code is first split into smaller chunks called tokens through the process of lexical analysis. Lexical analysis is also called tokenization.
The tokens are then parsed into a tree called the syntax tree by the parser.
An Abstract Syntax Tree (AST) abstracts out certain details, and retains just enough information to help the compiler understand the structure of the code.
Therefore, an AST is a tree data structure that best represents the syntactic structure of the source code.
Don’t worry if things aren’t clear just yet!
Over the next few minutes, you’ll draw a relatable analogy. And understand how the compiler works very similarly to how you'd try to make sense of a sentence.
Lexical Analysis
In this section, you’ll learn about lexical analysis.
Suppose you’re learning a new language—not a programming language though😄. And you’re given the task of inferring the meaning of a sentence in that language.
So how would you do it?

As a first step, you’ll try identifying the nouns, verbs, or more generally, words that matter. And lexical analysis is very similar to this step.
- Given the source code, the compiler tries to first identify the different types of tokens that your code is composed of.
- A token could be any valid entity in the programming language—a literal that takes a fixed value, a variable, an operator, or a function call.
As lexical analysis breaks down the source code into tokens, it is also called tokenization.
Syntactic Analysis
So far, you've learned that tokenization leaves you with tokens, or entities—just the way you’d identify entities in a sentence.
Let's go back to the analogy again.
After you’ve identified the nouns, verbs etc. in the sentence, how’ll you go about inferring its meaning?
Well, you’ll now try to parse the relationship between the nouns, verbs and the like—to see how they fit together—how they conform to the language’s grammar.

This leads to the step of syntax analysis, or parsing.
And to perform syntactic analysis, there’s a parser that processes these tokens and parses them into a tree called the Abstract Syntax Tree (AST).
More on AST Representation
Just the way the different entities and their relationships are often language-specific—the syntactic structure of a sentence in German may be very different from its syntactic structure in Hindi.
Similarly, there’s no one common AST representation and the actual AST structure may depend on the specific language.
In general, the AST models the relationship between tokens in the source code—as a tree comprising of nodes and the nodes containing children. And each node contains information about the type of token, and related data.
For example, if your node represents a function call, the arguments and the return values will be the associated data.
Let's draw the AST corresponding to the following equation:
2 + (z - 1)

In the above AST representation, the nodes + and - are operators, z is a variable, and 1 and 2 are just literals.
Notice how the parentheses are discarded in the AST—they're subsumed in the representation of (z - 1): z and 1 are both children of the - operator node.
Want to explore more on ASTs?
The AST Explorer helps in visualizing ASTs in several popular languages such as Go, Python, Java, and JavaScript.
Here's a simple example in Python:
my_str = "code more!"

Here, the type of node is VariableDeclaration as we declare the variable my_str.
Relevance of AST in Development
So where do AST show up in the development process?
In most languages, parsers that give you the AST will also give you the methods to traverse an AST.
This would enable you to visit different nodes of the AST to understand the functionality of each node, and additionally perform analysis.
So you can:
- define rules,
- traverse the parse tree by visiting each node, and
- check for violation of rules.
And this is where ASTs are relevant in static code analysis.
Static code analysis involves parsing of the source code into an intermediary representation on which you can run analysis, without actually running the code. And the intermediary representation is often the AST.
This analysis then returns potential security issues, bugs, and performance issues in your code - which you can fix almost immediately.
Conclusion
In this tutorial, you’ve learned:
- how lexical and syntactic analyses work,
- lexical analysis: identifies the tokens in the source code, and
- syntactic analysis: parses the relationship between these tokens to see how they fit together.
- how ASTs are tree representations of your source code, and
- how ASTs can help in static analysis
Thank you for reading. Hope you found this post helpful!